Trataremos de desmenuzar chuncanamente algunos conceptos de la IA. No por ello es un posteo liviano, de hecho es largo, pero espero que quien lo lea se lleve una visión un poco más iluminada de la caja negra que es la IA.
Este es un posteo de aprendizaje y de prueba, no debe ser usado como guía técnica y puede estar sujeto a errores. Es un posteo generalista por lo que muchos conceptos pueden no ser del todo correctos, dado el recorte realizado para poder leerse en un sólo post y con intención de que sea legible para cualquiera.

TL;DR
La IA es una función probabilística que procesa información en etapas: primero tokeniza y convierte palabras en vectores numéricos (embeddings), luego usa Self Attention para identificar relaciones entre palabras considerando el contexto, y finalmente genera respuestas. Los LLMs como ChatGPT son modelos decoder-only que funcionan calculando qué palabra es más probable que siga, basándose en patrones aprendidos durante el entrenamiento. Es matemática compleja a una velocidad bestial con una galaxia de datos.
IA
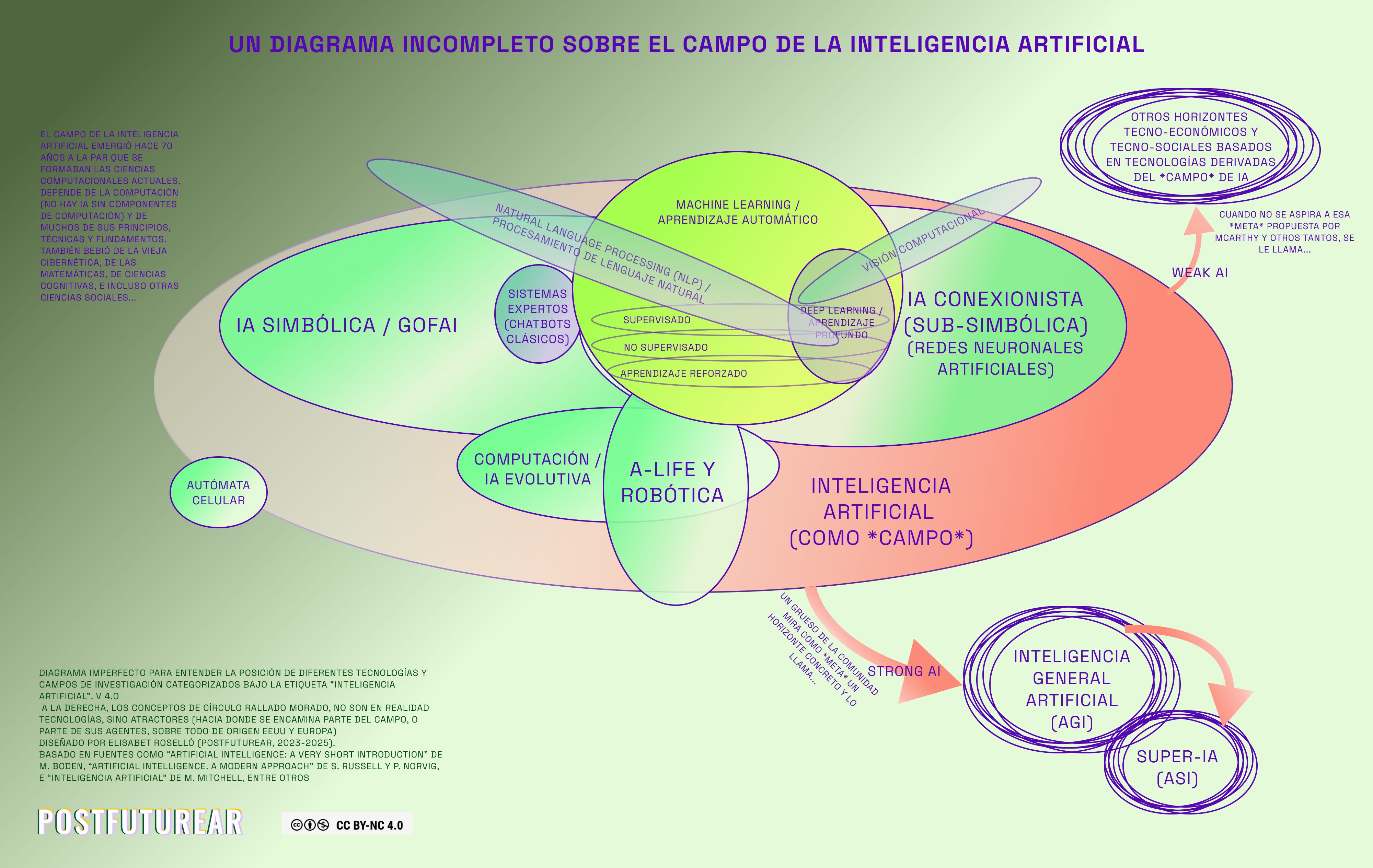
Arranquemos, la IA se llama así “inteligencia artificial” por una cuestión filosófica donde para no ligarla a la inteligencia humana, le pusieron artificial. (Entiéndase esto escrito de forma burda y expres, hay muchísimo de porqué se llama así y de si está bien o no, y demás debate) Pero por más que haga cosas increíbles sigue siendo una enorme función probabilística que realiza millones de cálculos en poquísimo tiempo generando texto, imágenes, o videos, que parecieran “reales” por una cuestión de que son construcciones realizadas en base a lo más probable.
Tenemos 3 tipos de “IA”:
-
Artificial Narrow Intelligence (ANI) - Inteligencia Artificial Estrecha
La IA que conocemos, sistemas de recomendación como “el algoritmo de netflis”, chatgpt, etc. -
Artificial General Intelligence (AGI) - Inteligencia Artificial General
Es teórica al día de hoy. -
Artificial Super Intelligence (ASI) - Superinteligencia Artificial
Teórica al día de hoy.
Hay más divisiones, dependiendo distintos aspectos.
Ver otros tipos de IA
Por Tipo de Salida
Por ejemplo también puede ser clasificada dependiendo su salida (lo que escupan los bichos estos).
| Tipo | Ejemplo |
|---|---|
| Predictiva | Predicción de demanda |
| Clasificatoria | Diagnóstico |
| Generativa | Texto / imagen (chatgpt, deepseek, etc.) |
| Prescriptiva | Qué acción tomar |
| Descriptiva | Análisis de datos |
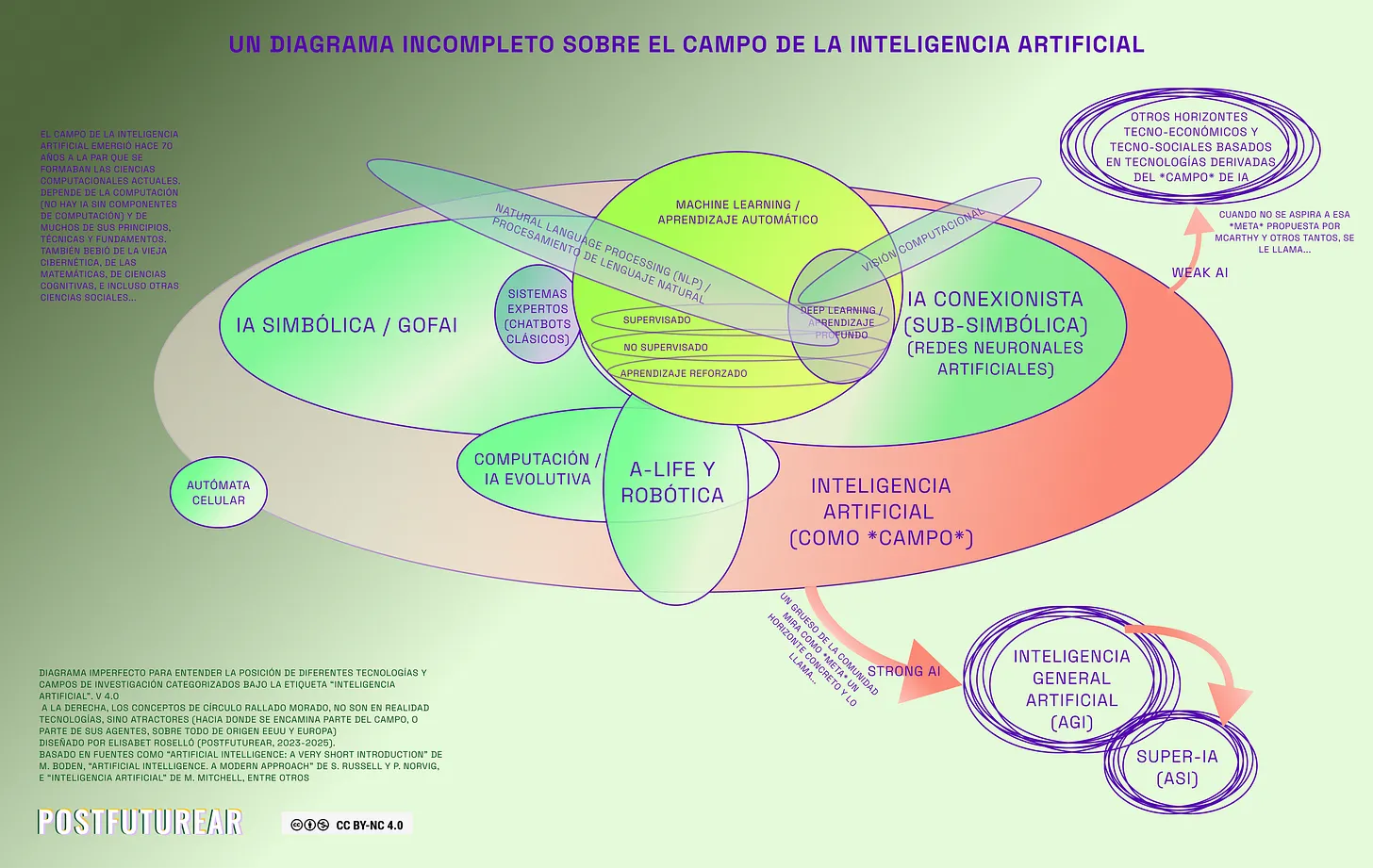
Imagen sacada del post “Introducción a la IA”
{kind=link}
Dentro de las ANI podemos dividirlas dependiendo como se las “entrene”:
- Supervised
- Unsupervised
- Semi-supervised
- Reinforcement learning
Pequeñísimo repaso de historia
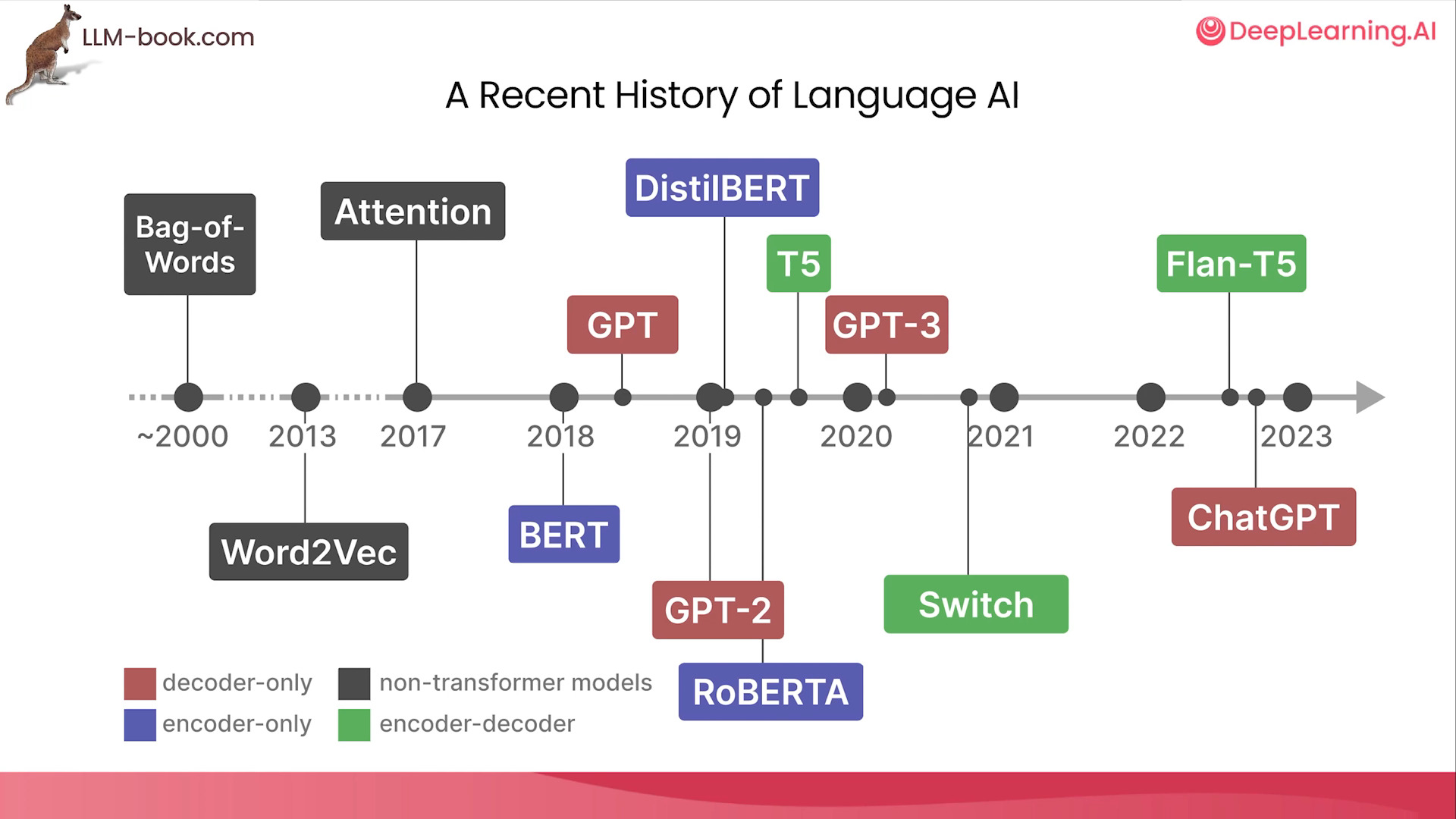
Imagen tomada del curso “How Transformer LLMs Work” - Jay Alammar, DeepLearning.ai
Esta imagen ilustra la evolución de una tecnología, desde ideas como Bag-of-Words Bolsa de palabras, Word2Vec Palabras a vectores, hasta lo popularmente conocido ChatGPT. Nótese el quibre de 2017, donde dice Attention, esa fecha fue la publicación de un paper que cambió el paradigma del Deep Learning, paper llamado “Attention its all you need”, que está citado en las referencias de este post.
En la imágen se pueden observar distintos tipos de LLMs.
- Decoder-only (GPT)
- Encoder-only (BERT)
- Encoder-Decoder (T5)
Otra forma de clasificarlos según su arquitectura
- Auto-regressive (GPT)
- Auto-encoding (BERT)
- Sequence-to-sequence (T5)
Estas diferencias de “Sólo Decodificador”, “Sólo Codificador” y “Ambos”, son diferencias de Arquitectura, osea cómo fueron construidos.
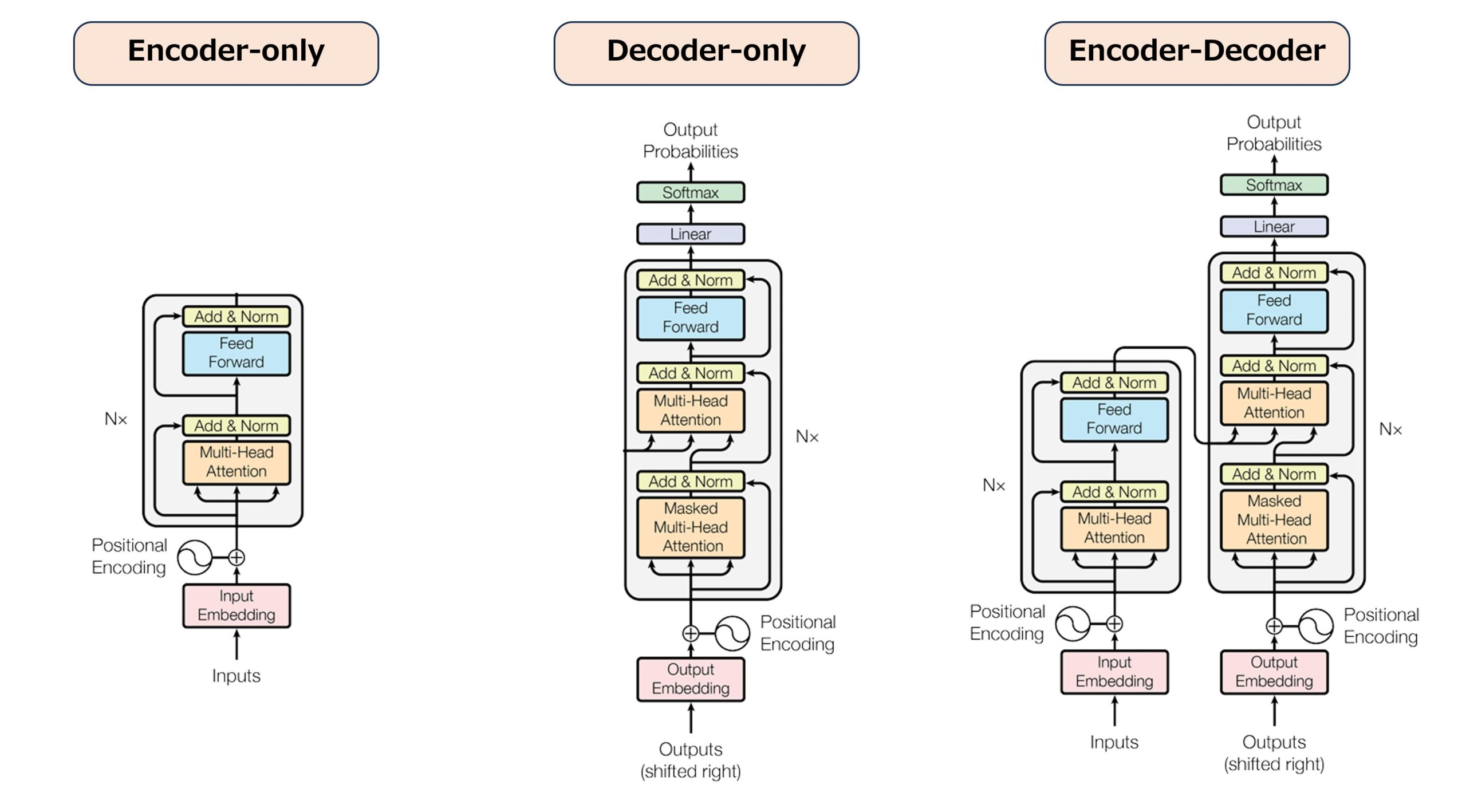
Fuente: DailyLifeAi
Se pueden observar similitudes entre arquitecturas, pero son diferentes, en el post trabajaremos con la llamada Decoder-only, por lo que pueden observar sus partes que luego desglosaremos.
Vamos a lo nuestro
La IA es un área muy abarcativa aunque al día de hoy se asocie sólamente a ChatGPT. Hay una rama dentro de la IA que es llamada Machine Learning (Aprendizaje Automático), dentro de esta rama se encuentra otra rama llamada Deep Learning (Aprendizaje Profundo), y dentro del Deep Learning está la IA Generativa, que es la que utilizamos. (ChatGPT, Claude, DeepSeek, etc).
ANI → Machine Learning → Deep Learning → Generative AI.
No todo el machine learning es generativo, no todo deep learning es generativo. La IA generativa es un tipo de modelos de Deep Learning.
Por ejemplo las traducciones, los sistemas de recomendación de compras, o películas, son parte de la IA, pero no es IA generativa. Lo que más usamos son LLMs “Large Language Model”, grandes modelos de lenguaje, reitero: tales como ChatGPT, Claude, DeepSeek, etc, que son un tipo de IA Generativa. Cuando hablamos de LLMs hacemos referencia a lo que se llama “modelo”. ChatGPT, Claude, DeepSeek, etc, son más que sólo un modelo porque son aplicaciones, dentro de ellas podés elegir distintos modelos y hacer más cosas, ustedes que los usan sabrán mejor que yo.
Se puso jodido el post pero es complejo comentar estas cosas, y además peco de poner cosas “simplificadas” con cosas “complejas” haciendo un posteo generalista.
Basaremos el post analizando sobre un LLM GPT (Generative Pre-Training), osea un modelo de IA Generativa que es decoder-only, dado que citaremos una página que está muy linda, que permite ver uno de estos modelos paso a paso.
| Arquitectura Decoder-only | Arquitectura NanoGPT |
|---|---|
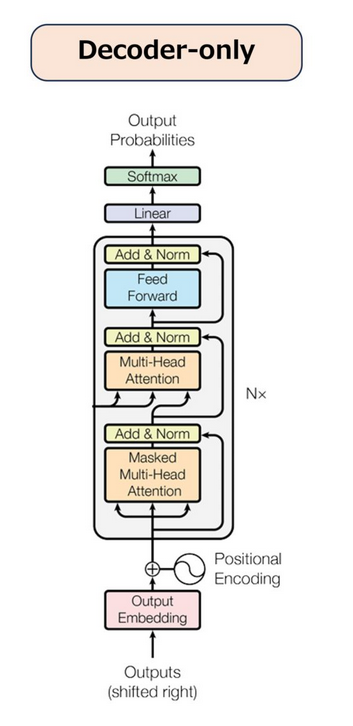 Fuente: DailyLifeAi Fuente: DailyLifeAi |
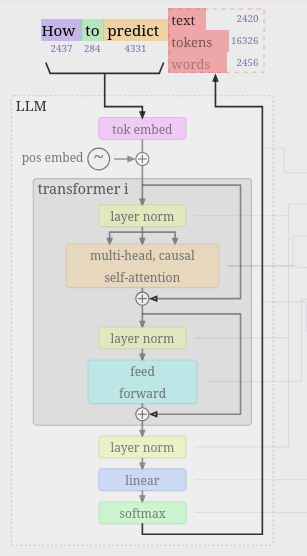 Fuente: LLM Visualization Fuente: LLM Visualization |
En la web propuesta se observa un decoder-only con alguna que otra variación respecto a la arquitectura estándar que está a la izquierda en la imágen. Quizás para ubicarse visualizar las “Add & Norm” que son las mismas que las “layer norm” en color amarillo.
Por lo que el posteo será hablar de sus etapas, o capas:
- Tokenizer/Embedding
- Self Attention
- MLP/ FeedForward
- Output
Hay otras capas adicionales que se utilizan:
- Normalización (Layer Normalization)
- Conexión Residual (Residual)
- Linear
- Softmax
Estas capas no las explicaremos dado que son bastante teóricas y relacionadas fuertemente con aritmética de computadoras y probabilidad.
Lo primero: Tokenizer/ Embedding
La máquina no entiende como nosotros, por lo que para “entender” necesitamos partir el texto ingresado. Cada “IA” parte el texto en distintas formas. Pueden jugar ingresando distintos textos en el Tokenizer de OpenAI y ver cómo se “tokeniza”/”recorta” dependiendo el modelo.
Usaremos la traducción a la frase de Batty: “Quite an experience to live in fear, isn’t it? That’s what it is to be a slave.”
Cuya traducción un poco a mi forma aprox: “Es una locura vivir con miedo, no? Eso es ser esclavo”.
| Modelo | Tokenización |
|---|---|
| GPT-4o | 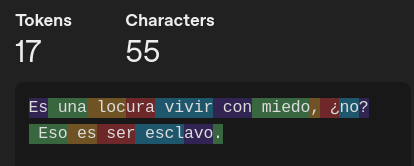 |
| GPT-3 | 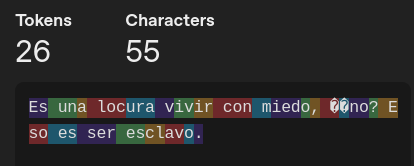 |
Así es, a partir de ahora introducimos el concepto de tokens que son las divisiones que hará cada modelo para poder “entender” nuestras frases. En criollo recortes de nuestra frase, tal como se ve en las imágenes de arriba.
Ver otros tipos de tokenización
- Tokenización basada en palabras (Word tokenization)
- Tokenización basada en subpalabras (Subword tokenization)
- Tokenización basada en caracteres (Character tokenization)
- Tokenización basada en símbolos (Symbol tokenization)
- Tokenización basada en frases o unidades lingüísticas más grandes (Phrase tokenization)
- Byte-level BPE (a nivel de bytes), como usa GPT-2
- WordPiece, usado por BERT
Se puede ver y leer mucho más sobre esto en el Curso de LLMs de Hugging Face
La misión ahora es tratar de tener en cuenta cada pedacito recortado. Luego convertiremos cada pedacito o token en un vector numérico y lo llamaremos Embedding. Para diferenciar cada token se usan los Token Embeddings y para saber información acerca del órden que aporta cada palabra se usan los Positional Embeddings. Ya que la compu no sabe (La arquitectura usada no sabe por sí mismo cuál es el órden de un token en la secuencia de tokens). Entonces para cada token hay un Token Embedding, Position Embedding, que cada uno representan: El token en sí, y el órden que ocupa el token en la frase.
Porqué necesitamos el orden? Coherencia.
No es lo mismo decir:
“Mañana tengo que ir al banco a sacar plata.”
Que decir:
“Plata a sacar banco ir al mañana que tengo”
Por lo que es necesario “recordar” con los Position Embeddings el orden de las palabras en la frase. Todo esto está basado fuertemente en la lingüística, proviende del Procesamiento del Lenguaje Natural (NLP).
Tokenizemos y embeddiemos una palabra(?
Para más facilidad en este ejemplo utilizemos “Tokenización basada en palabras” donde cada token representa una palabra, como vimos debemos convertir cada palabra en un “token”. Tomemos una palabra como ejemplo: “Maradona”
- Tokenización →
token = "Maradona" - Asignación de ID →
token_id = 18427 - Conversión a embedding →
embedding = [0.91, -0.33, 1.27, 0.08, -0.54, 0.62]
Resultado:
- Token: qué palabra es (“Maradona”)
- Token ID: identificador numérico único (18427)
- Embedding: representación vectorial numérica de la palabra
El modelo no entiende de tokens, sólo entiende de embeddings.
Sucede una gran magia en los embeddings que es media compleja asi que no la explicaremos acá, y esa transformación a un vector seguro les pierda porque falta explicar una parte, pero quedense con lo visto.
- Token Embedding: va a representar qué es “Maradona”, y se va a ir recalculando.
- Positional Embedding: va a representar dónde está el token en la frase.
Buscamos entonces sumar ambos vectores generando así el Input Embedding.
\[\text{Input Embedding} = \text{Token Embedding} + \text{Positional Embedding}\]Como si fuera ArtAttack nos quedaremos con este resultado sacado sin fundamento, pero para que se vea qué es lo que se enviará a la primer etapa del tranformer.
Input embedding (“Maradona”, posición 0) = [ 0.93, -0.18, 1.16, 0.48, -0.47, 0.53 ]
Bueno pero retomemos nuestro ejemplo con la frase de Batty, donde no se utiliza el tokenización por palabra:
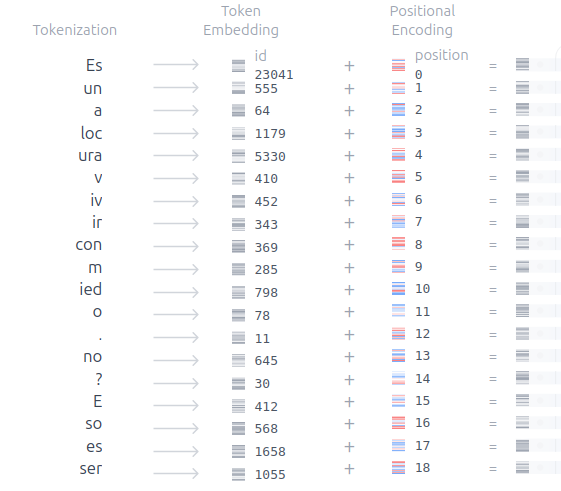
Ahora ya sabemos que los “Embeddings” son los tokens vectorizados, osea los tokens convertidos en vectores de números, que nos permiten capturan la información semántica y sintáctica de las palabras que representan.
Self Attention
Es la parte más densa de la lectura
Esta parte es donde se trata de identificar que relación hay entre cada palabra, por ello es un cálculo de cuánto afecta la representación de un embedding contra todos los otros embeddings. Permite capturar significados y relaciones entre tokens. A esto se le suele sumar Multi-Head Attention, lo cual son varias “cabezas de atención” lo que sería comparable con la idea de prestarle atención a distintas partes de la frase, con la aplicación de la multicabeza se puede prestar atención a más patrones, y por ejemplo a dos frases separadas, etc.
Vamos a tomar el ejemplo de Santiago Fiorino:
“Mañana tengo que ir al banco a sacar plata.” / “Nos sentamos en el banco de la plaza a tomar mate.”

Encima de cada palabra está su respectivo embedding, notar como la palabra banco tiene el mismo embedding pero se usa en frases con contextos distintos, donde uno tiene relación con una entidad financiera y el otro con un asiento. Para poder entender dicha situación, el humano interpreta el contexto donde está ubicada la palabra. Para ello se tiene en cuenta cuánto debería afectar cada palabra a cada otra palabra, por ejemplo la relación entre banco y plata debería ser mucho más significante que la relación entre banco y mañana.
“Para ello generamos una matriz NxN, donde en cada posición de la matriz estará en un valor numérico la respuesta a cuánto debería influir la palabra ‘i’ a la hora de actualizar la palabra ‘j’” - Santiago Fiorino.
Matriz de Query: representa lo que estamos buscando en los otros tokens
Matriz de Key: representa la “clave”, qué tan inportante es un token para el otro token que estamos analizando.
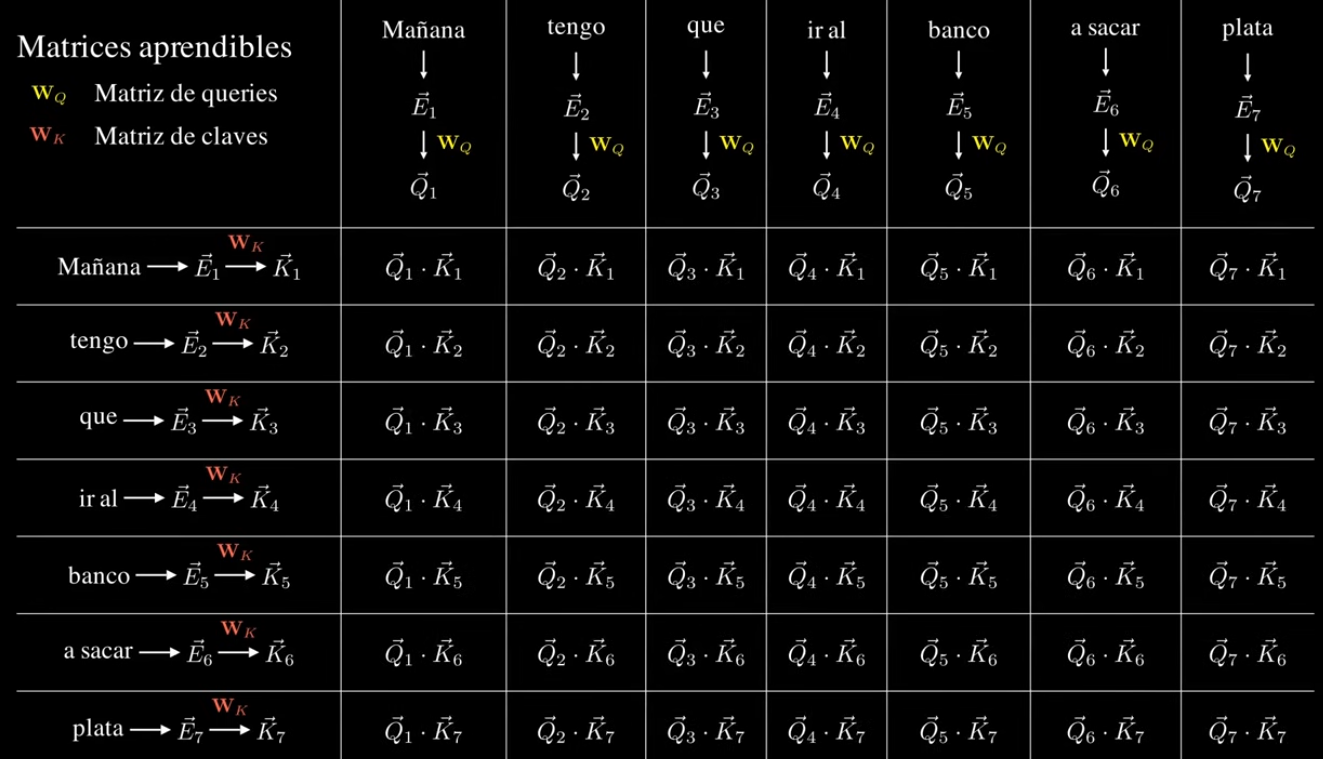
Ejemplo de Santiago mostrando cómo se crea la matriz Q⋅K
Entonces esos valores que den se “normalizan” para que queden en números entre 0 y 1, donde si entre dos palabras el valor es 0 entonces no tienen relación entre sí, por lo contrario si el valor es 1, entonces tienen una relación importante entre sí.
Con las anteriores matrices sabemos cuánto tiene que afectar una palabra a otra pero no “como”, por ello viene esta tercer matriz.
Matriz de Value: información real.
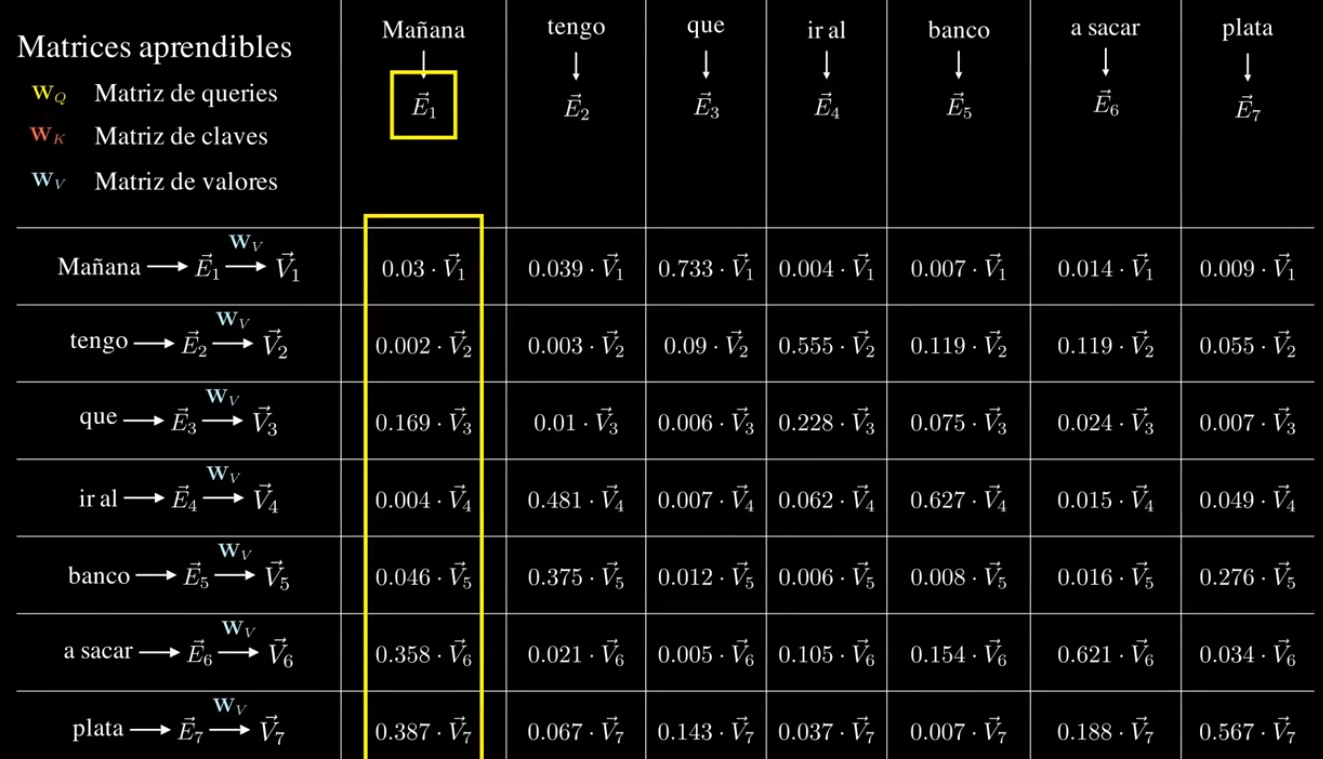
Con eso obtenemos una matriz de valores con toda la información necesaria.
Esto tiene una fórmula terrorífica que es:
\[Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V\]Esto permite realizar un cálculo de relaciones entre todas las palabras, teniendo en cuenta distintos factores, donde además mientras se entrene y reentrene, va a permitir calcular las probabilidades de cuantas veces determinada palabra está “cerca” de otra y bajo un mismo “contexto”. Por lo que estas relaciones permiten que el modelo “aprenda” qué palabras están más relacionadas en diferentes contextos. Esto agregado con la capa de MLP o FeedFordward se “recalcula” y de esta forma el modelo “aprende”, que como vimos no “aprende” sino que calcula.
MLP/ FeedForward
Esto es complejo pero aquí se aplica una red neuronal, que mejora el modelo, y se introducen funciones no lineales como la famosa ReLU (Rectified Linear Unit), esta parte puede ser vista como una minimización de la función de costos (Esto me lo hizo ver ezeluduena). Utilizando el descenso del gradiente. Acá hay mucho para hablar, participan factores muy populares como la entropía, y el error cuadrático medio. Para cualquier persona que no sea de la temática medio que puede saltarse a la prox etapa que sería la de output, dado que ya “aprendió” como funciona un LLM.
La no-linealidad y ver que estamos buscando una minimización o “maximización” queda más claro al ver esta figura, y por eso el descenso del gradiente es una buena técnica para encontrar esos mínimos.
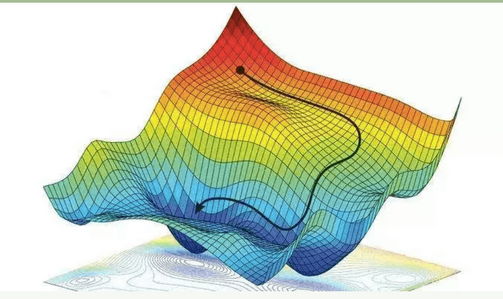
Para flasharla un poco más dejo esta filmina de Victoria Peterson
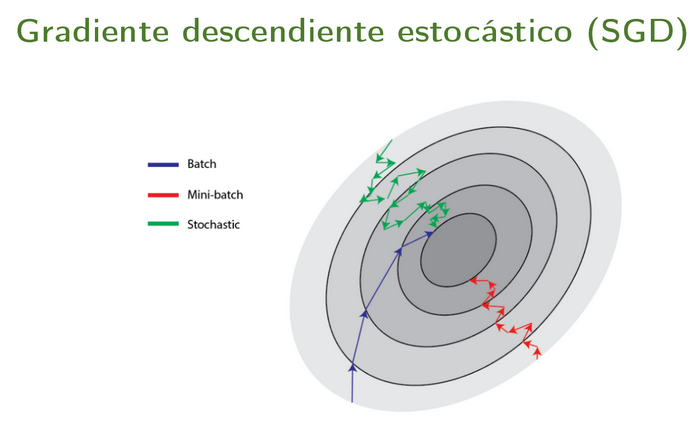
Y el link al collab que es buenísimo de ella.
Output
Obtendremos una lista de probabilidades para la palabra siguiente
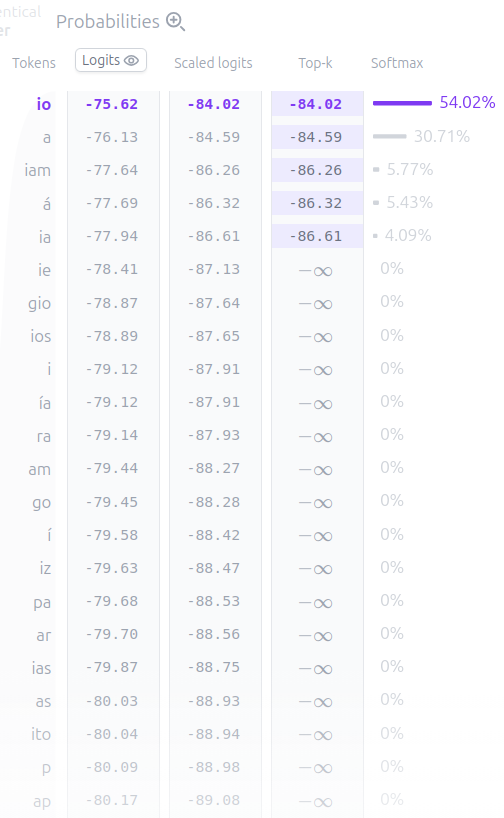
También podemos controlar la suavidad de la distribución mediante un parámetro de temperatura. Una temperatura más alta hará que la distribución sea más uniforme, y una temperatura más baja la concentrará más en los tokens con mayor probabilidad.
Fin
Gracias por leer el post, espero que haya aclarado un poco más esto de los LLMs, y algunas cosas de la IA. Se irán agregando posteos para profundizar en distintos aspectos mencionados en el post. Recomiendo fuertemente las referencias, en particular los links que son interactivos como:
- Transformers Explainer
- Generative AI exists because of the transformer
- LLM Visualization
- Interactive Variational Autoencoder
Referencias
- Introducción a la IA Generativa
- Generative AI exists because of the transformer
- LLM Course - Hugging Face
- LLM Visualization
- Understanding Tokenization: Breaking Down Language for AI systems
- How are Large Language Models trained? A step-by-step guide to LLM training
- Interactive Variational Autoencoder
- Deep Learning - Wikipedia
- Weak artificial intelligence - Wikipedia
- Tokenizer - OpenAI
- Curso de LLMs de Hugging Face
- Improving Language Understanding by Generative Pre-Training
- GPT - Hugging Face Docs
- BERT - Hugging Face Docs
- Attention Is All You Need
- Transformers Explainer
- Blade Runner - Tears in the rain
- Interactive Learning of Text-Generative Models - Paper